
.png?width=141&height=141&name=Transact%20(1).png)










Compared to even a decade ago today's IT infrastructures are like something from another world.
Enterprise organizations who have adopted cloud-native technologies and services are having to manage complex distributed systems, where application design is changing all the time.
IT teams are quickly discovering that traditional monitoring tools alone are no longer adequate, and the skills and processes that were once sufficient for keeping track of networks and applications are constantly becoming redundant.
The applications used in today's modern distributed systems are designed to be more agile so that they can adjust to changing business needs, service level objectives, and new multi-cloud ecosystems. But software engineering teams who have invested heavily into complex systems, are finding that their existing monitoring and observability strategies are providing only limited insights and business value amid spiraling costs.
In this guide, we'll explain the true value of observability tools, and why having a sound observability platform is essential for application performance management.

Image source: DEJ
What makes observability important?
Through observability in IT and cloud computing, IT teams can accurately measure, monitor and analyze the health, performance, and status of software systems, based on its external outputs.
A system is considered “observable” if you can determine its current state by only using information from its system's outputs, or sensor data.
Today, observability tools are used to improve the performance of distributed IT systems, and enterprise organizations rely on their observability strategy to keep their IT systems up and running smoothly.
Facts, together with high quality, accurate system data allows organizations to make decisions, that give them the power and control they need to maximize business impact.
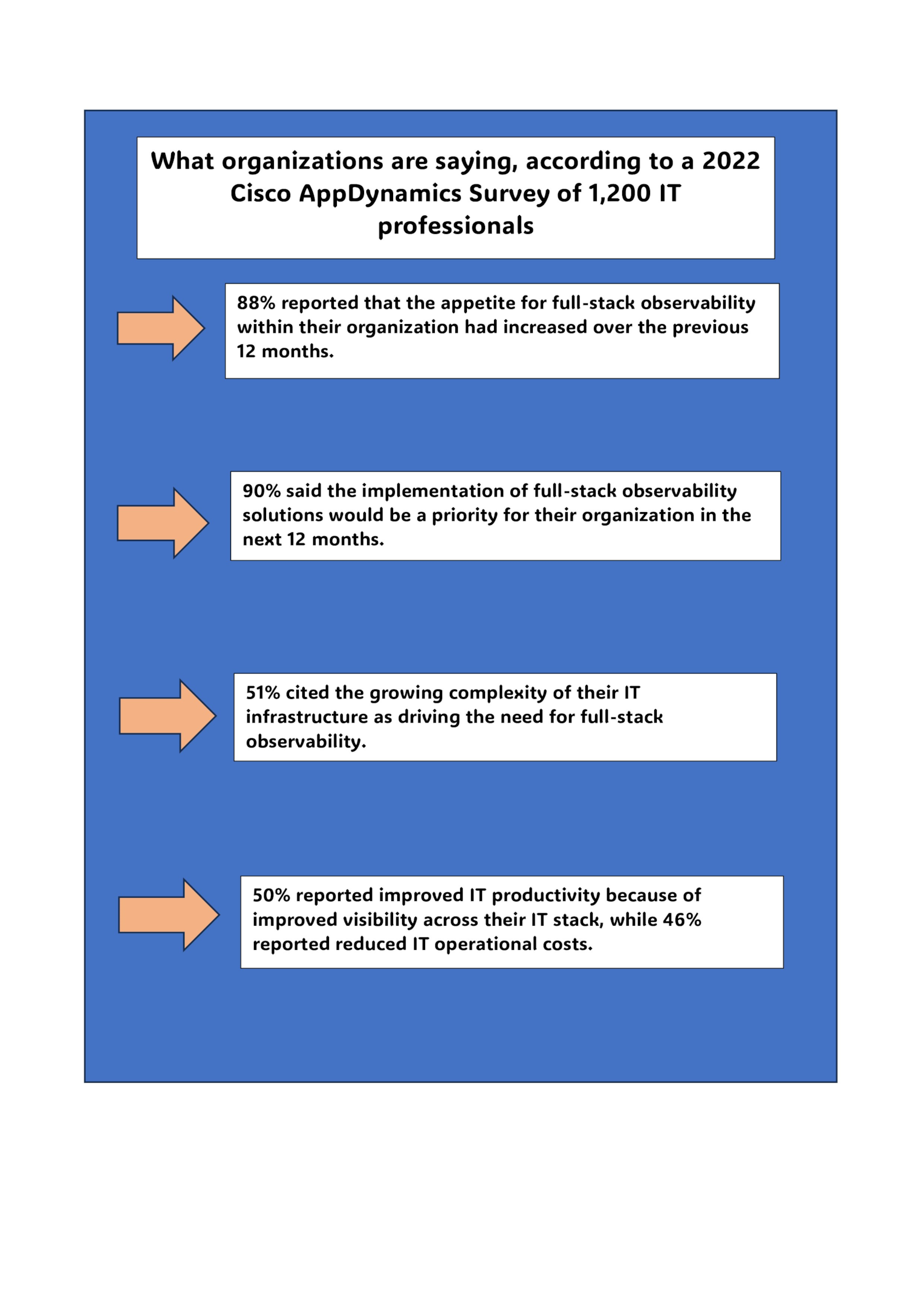
According to data collected from a 2022 Cisco AppDynamics survey of 1,200 IT professionals:
88% reported that full-stack observability within their organization had increased over the previous 12 months.
90% said the implementation of full-stack observability solutions and monitoring tools would be a priority for their organization in the next 12 months.
51% cited the growing complexity of their IT infrastructure is driving the need for full-stack observability.
50% reported improved IT productivity because of improved visibility across their IT stack, while 46% reported reduced IT operational costs.
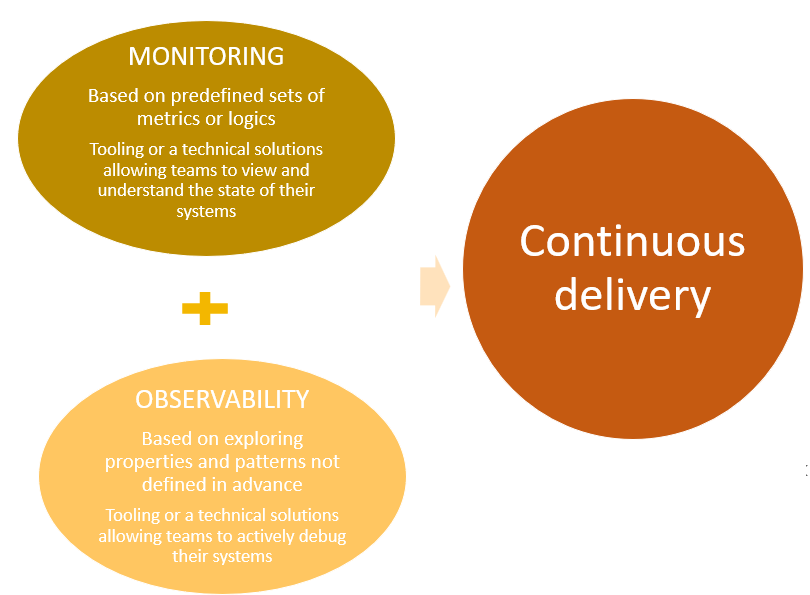
Observability vs monitoring - what's the difference?
While the two terms are often interchangeable, and taken to mean the same thing, they're actually different.
Monitoring observes a system’s performance in real time, over a period of time. Monitoring tools collect and analyze performance data, then translate it into actionable insights.
Observability addresses the internal state of a software system from knowledge of its external output. Observability uses the data and insights produced by monitoring to provide a deep understanding of your whole system, including performance and overall system health.
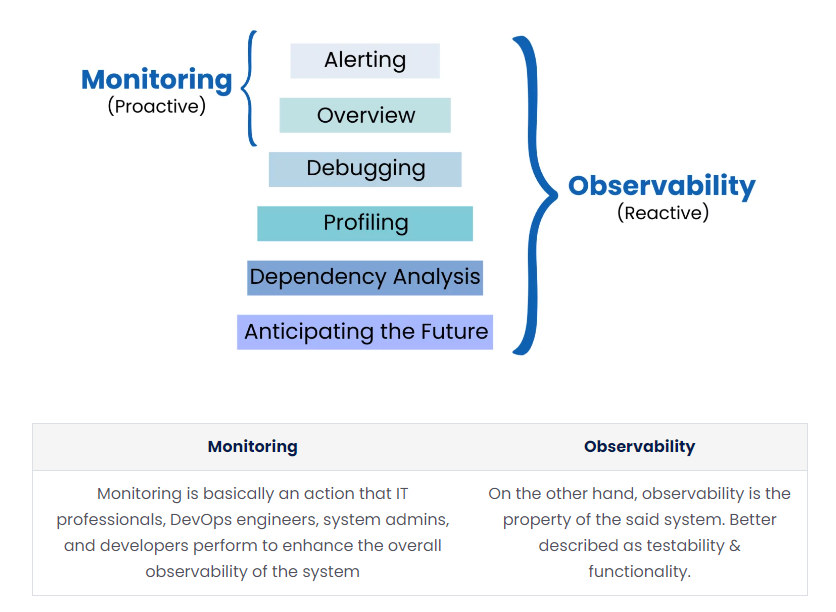
Image source: Cloud Zenix
How control theory relates to observability
This refers to the process of maintaining stability and predictability within a complex digital system to achieve observability.
Put simply, through control theory, observability can measure the internal states of a system from knowledge of its external outputs. This means software engineers are able to make sure that processes and applications run smoothly and efficiently by creating an observable system. Without proper observation of cloud systems, those systems can't be expected to perform optimally.
By using principles such as feedback loops and error correction mechanisms, businesses can constantly monitor and adjust their systems to ensure seamless performance.
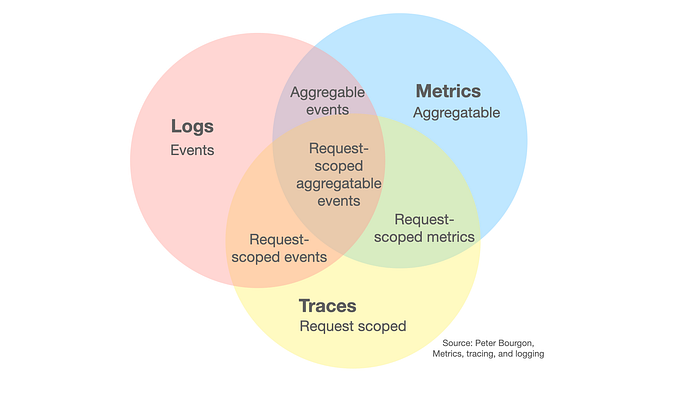
Telemetry data: The three pillars of observability
Observability uses three basic types of telemetry data to gain deep visibility into a distributed system and find the root cause of issues with system performance. Each type of telemetry data collected reveals a unique perspective on a system’s behavior, and this allows teams to better understand software application performance and system health.
The unification of these data types creates a more comprehensive picture of software systems, and help to address the 'unknown unknowns' - or the issues that you are unaware of - enabling faster identification and resolution of issues.
Let's look at the three telemetry data types, logs, metrics and traces:
Metrics
Metrics provide real-time insight into the performance and health of a software system or IT infrastructure, allowing actionable insights within a complex system. Common metrics are CPU utilization, latency, network traffic, or user signups.
Logs
Logs are a record of events and structured and unstructured lines of text that a system produces in response to certain codes within an application, or software environment. They show when a problem occurred and which events correlate with these records.
Traces
Traces provide insight into the flow of an application. Trace observability allows you to see the source of issues and to identify the root cause, even in distributed systems like microservices and containers. Trace tools are sometimes incorporated into the software development process to gain full visibility
How do you implement observability?
Observability tools give software engineers and software developers the power to greatly enhance customer experiences, even with the increasing complexity of the digital enterprise.
With observability, you can collect, explore, alert, and correlate all telemetry data types. Observability makes it easier to drive operating efficiencies and fuel business growth.
Want to know more? Read our guide.
How Data Observability Empowers Informed Decisions
Benefits of observability
The key benefit of an observability solution is that it can provide multiple stakeholders within an enterprise organization with actionable insights into an increasingly complex, multilayered, and distributed IT infrastructure.
Growing data volumes are causing this complexity to increase, highlighting the importance of data aggregation.
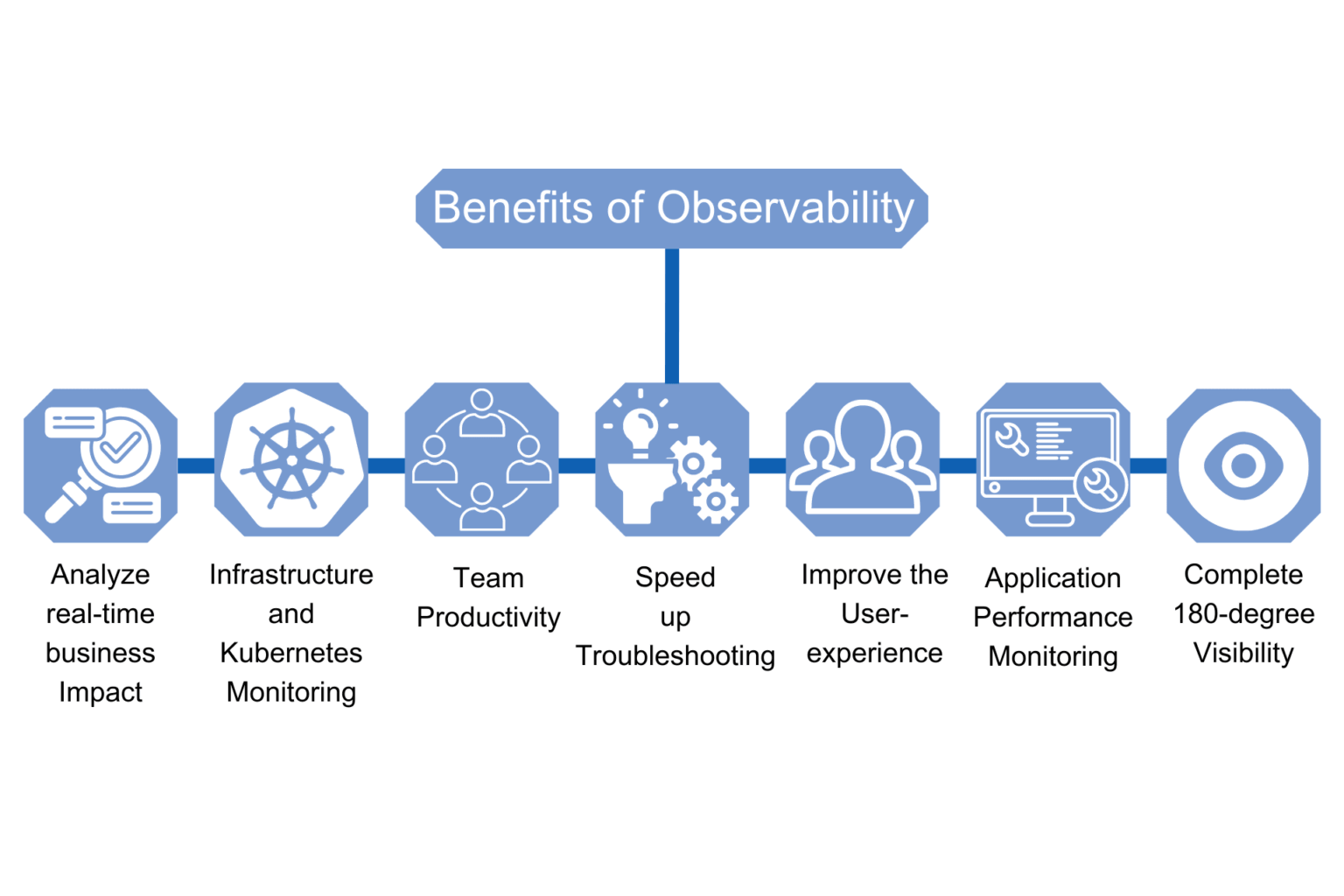
Image source: CloudZenix
Comprehensive actionable insights
Any system issue that threatens user experience can be improved by a unified observability platform. Through the deeper visibility provided by observability, developers can quickly find and fix problems, and can see what, if anything has changed in the system. This includes fixing network issues and a reduction in Mean Time To Detect (MTTD).
Drives agile development
When it comes to reliability and application key performance indicators, observability significantly helps push applications faster with fewer problems, less downtime and better correlation of incident data. And when there are issues, they can be resolved more quickly and efficiently.
Monitor Trends
An observability tool can monitor trends, and get ahead of issues before they impact your system. Observability's power is in the way it proactively tracks how systems perform, predicting and preventing similar issues from occurring again in the future. An observability platform improves incident response by enabling IT engineers to ask questions of data that they didn’t previously know they needed to ask.
Foresee a Data Breach
Security breaches can cost millions in damages, destroy a company’s reputation and irreparably damage customer trust. Observability tools can inform teams well in advance if there’s a threat looming, and help teams to gain quick control before it’s too late.
Real-time analysis
The ability to turn real-time data into real-time analytics helps make better decisions that can positively impact end users. For example, enabling customers on an eCommerce site to find out instantly how much inventory is available in real time. Or alerting a bank customer immediately if there is fraud detected on their card. Real-time data provides greater visibility into a dynamic system with immediate insights to significantly improve customer experiences, and help to better manage inventory and improve operations.
Best practices to achieve system observability
Every organization should establish a set of observability best practices to provide guidelines for sustained and efficient development. These need to be compliant with standards and regulations while providing a path for continuous improvement.

Image source: Cribl
1. Know your platform
Different platforms and systems require different observability and monitoring approaches and it's important to understand the unique characteristics of your platform such as:
-
Platform components, dependencies, and communication patterns.
-
Workloads running on your platform, like real-time services, background tasks, batch jobs etc.
-
The operating system's performance characteristics, resource utilization, and limitations
2. Decide what to monitor
IT platforms generate huge volumes of data, but not all of it is useful. When it comes to data collection, observability systems should filter data close to the source, at multiple levels, to avoid cluttering with excess data.
3. Create alerts only for critical events
Alerts should be configured to send notifications for a critical event, for example when an application is behaving outside its predefined parameters. Machine learning models can automatically correlate and prioritize incident data. This helps to filter out unwanted alert noise, and detect issues that can impact the system. A properly configured alert system ensures that developers know when an issue has to be fixed so they can stay focused on other tasks.
4. Customize your dashboards
Relying on default dashboards means that you won't be able to capture the unique characteristics of each system. A system that allows you to customize dashboards will highlight important metrics specific to the system, and provide insights into the performance of critical components. This makes it easier for IT departments to analyze and interpret data.
Find out how to keep your IT systems working at optimum capacity.
How IR Collaborate can help
Monitoring, and observability are a set of capabilities that together create better data quality, increased software performance, optimal user experience and organizational output. IR Collaborate can help with both monitoring and observability.
Finding and resolving a problem quickly within your IT infrastructure is critical for successful business operations. But the key to locating issues efficiently is having comprehensive monitoring tools to identify problems in real time.
Quickly monitor and troubleshoot: IR Collaborate can help you find and fix the root-cause of problems quickly so you can maximize performance throughout your system and minimize user impact.
Complete visibility through a single pane of glass: With one dashboard for end-to-end visibility you can streamline IT processes and operations across your entire IT environment.
Deploy the way you want: Our versatile solutions can be deployed in the cloud, on premises or as a hybrid model.
More than 1,000 organizations in over 60+ countries - including some of the world’s largest banks, airlines and telecommunications companies rely on IR Collaborate's solutions and insights to ensure optimal performance and user experience.
Monitor, troubleshoot, analyze and optimize critical systems with IR




